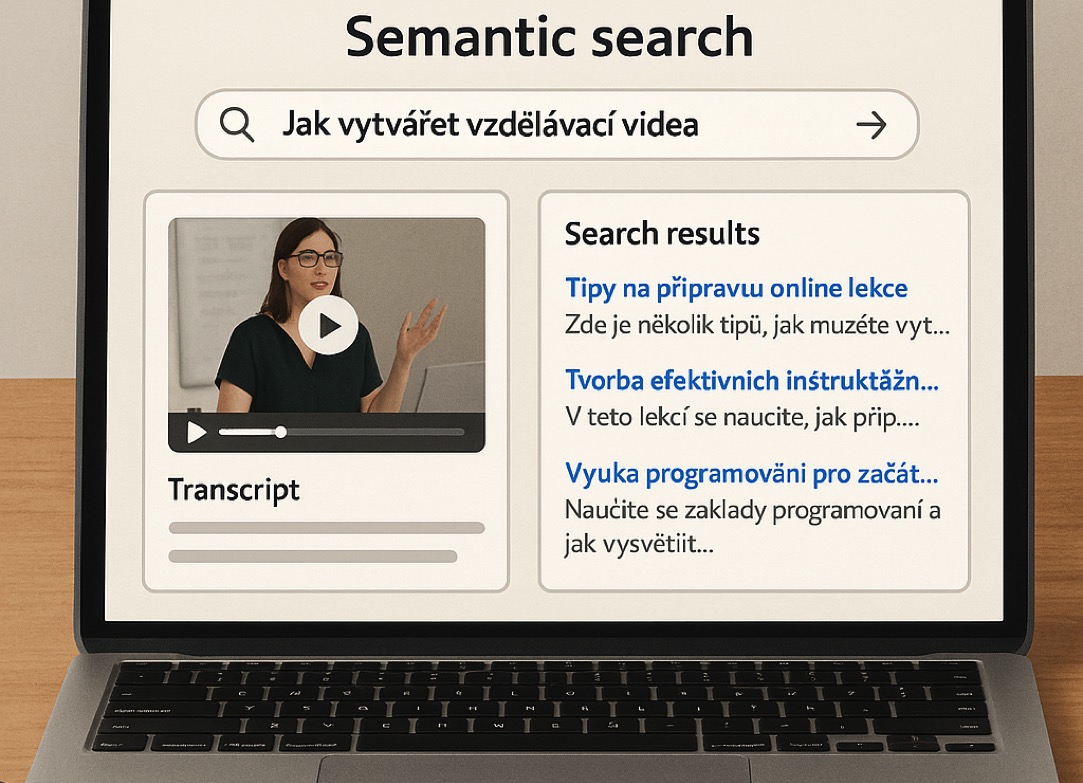
Cílem bylo zpřesnit výsledky vyhledávání na webové stránce, která slouží pro přístup k rozsáhlému množství vzdělávacího obsahu včetně placených videí. Původně zvažované fulltextové vyhledávání mělo svá omezení – neporozumělo významu dotazu a vyžadovalo přesné zadání slovních spojení. Zaměřili jsme se na vytvoření snadného vyhledávání, které umožní uživatelům psát dotazy běžným jazykem a přesto získat co nejrelevantnější výsledky.
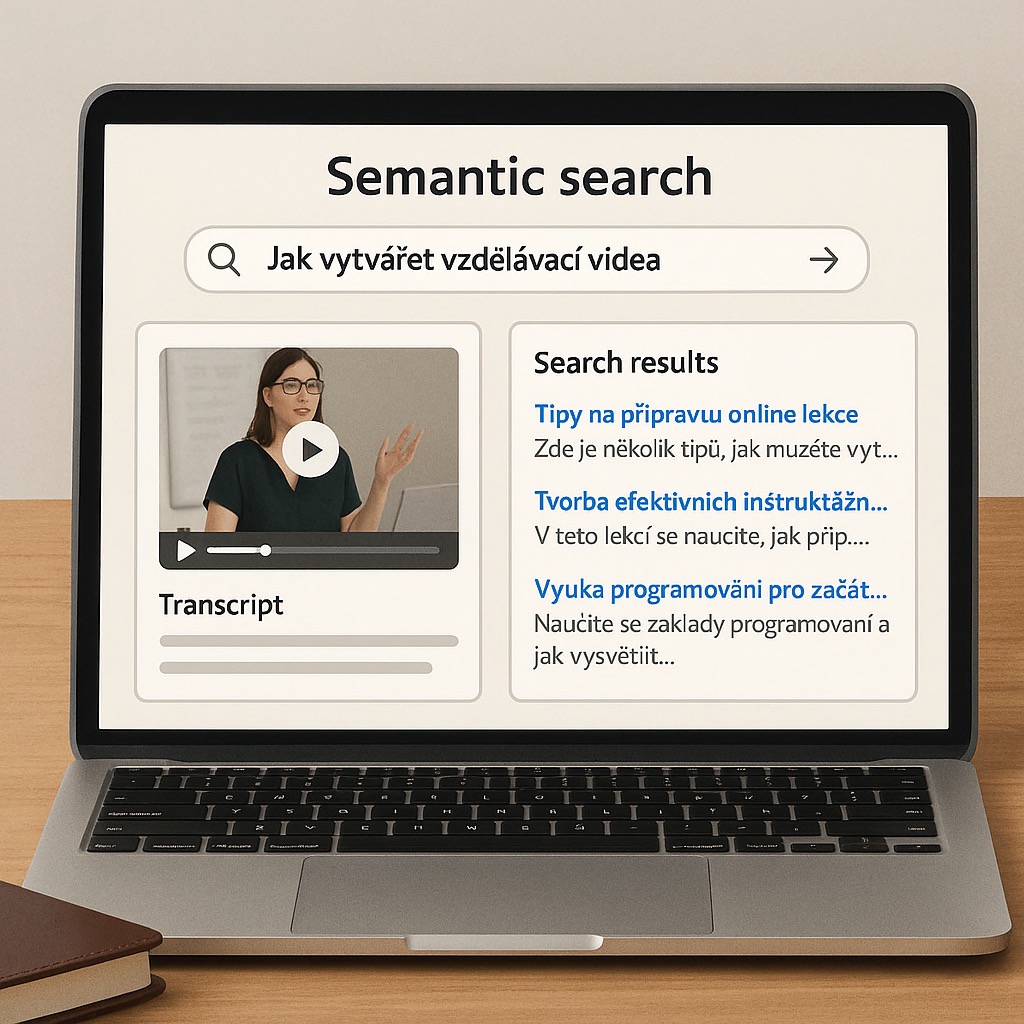
Upravili jsme vyhledávání tak, že nyní pracuje s významem dotazu a přináší přesnější výsledky bez ohledu na konkrétní formulace. Do vektorové databáze jsme integrovali nejen transkripty placených videí, ale i obsah celého webu, který pravidelně zpracovává vlastní crawler. Ten běží jako součást webové aplikace a po každé aktualizaci stránek odesílá nový obsah pomocí REST API a Cronu na externí zařízení s Linuxem, kde je připraven k dotazování AI algoritmem ve vektorové databázi.

Samotné vyhledávání funguje tak, že uživatel zadá dotaz běžným jazykem. Python skript volá sémantický model (LaBSE), který vrací výsledky dle významové podobnosti. Systém podporuje vícejazyčnost a rozpoznává jazyk dotazu, díky čemuž správně pracuje i se smíšenými daty. Dbali jsme na výběr technologie s plnou podporou češtiny včetně diakritiky.