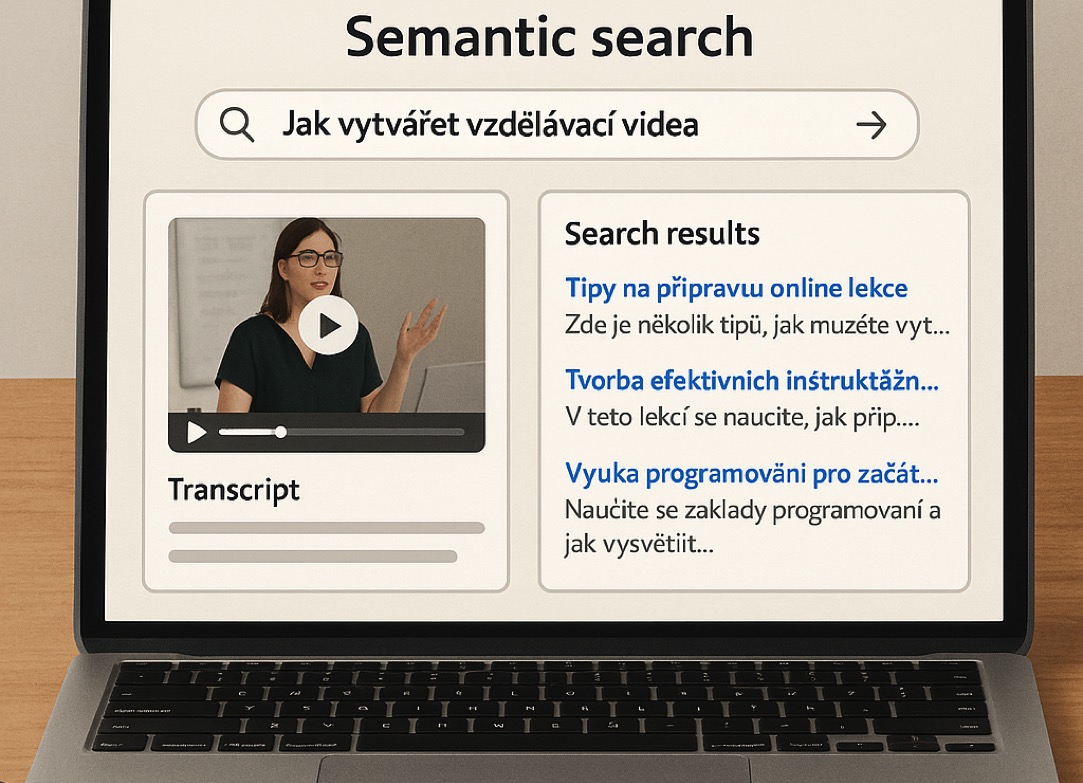
The goal was to improve the accuracy of search results on a website providing access to a wide range of educational content, including paid videos. Traditional full-text search had limitations—it couldn’t understand query meaning and required exact phrasing. We focused on building user-friendly semantic search that lets users ask questions in natural language while still receiving the most relevant results.
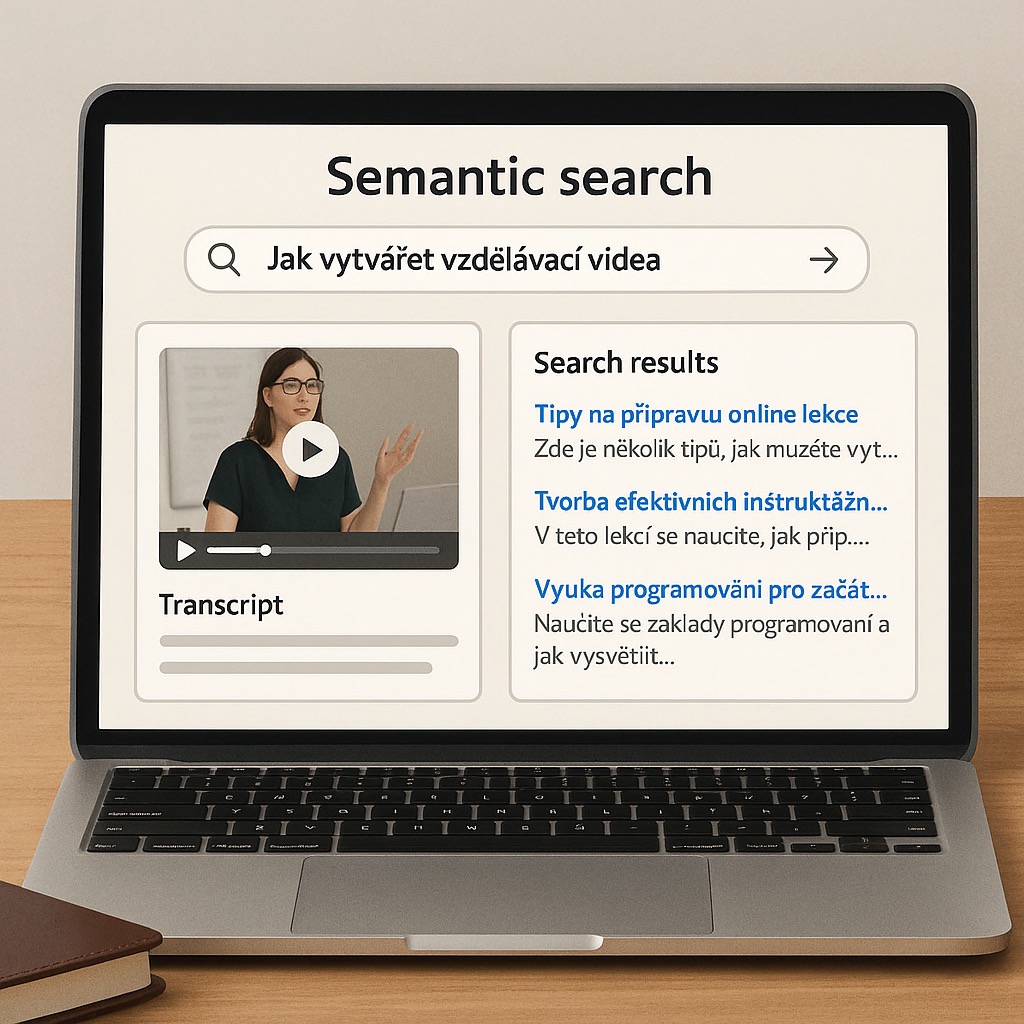
We redesigned the search to work based on meaning rather than wording. Into a vector database, we integrated not only video transcripts but also full website content, which is regularly processed by a custom crawler. That crawler is part of the app and after every page update sends content via REST API and Cron to a Linux-based machine, where it’s ready for AI semantic queries.

The user types in any natural language query. A Python script calls the semantic model (LaBSE), which returns semantically similar results. The system supports multilingual queries and detects the language, correctly sorting results even from mixed-language datasets. We selected technology that fully supports Czech including diacritics.